Research
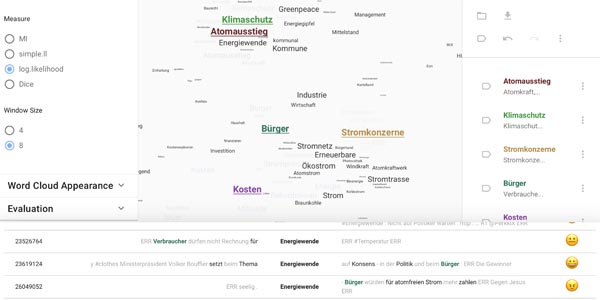
The Chair of Computational Corpus Linguistics carries out foundational methodological research on the quantitative analysis of large text corpora. The algorithms and software tools developed by the group support innovative studies in the digital humanities and social sciences as well as practical applications in language technology. A particular focus lies on understanding cooccurrence phenomena and their application in corpus-based discourse analysis.